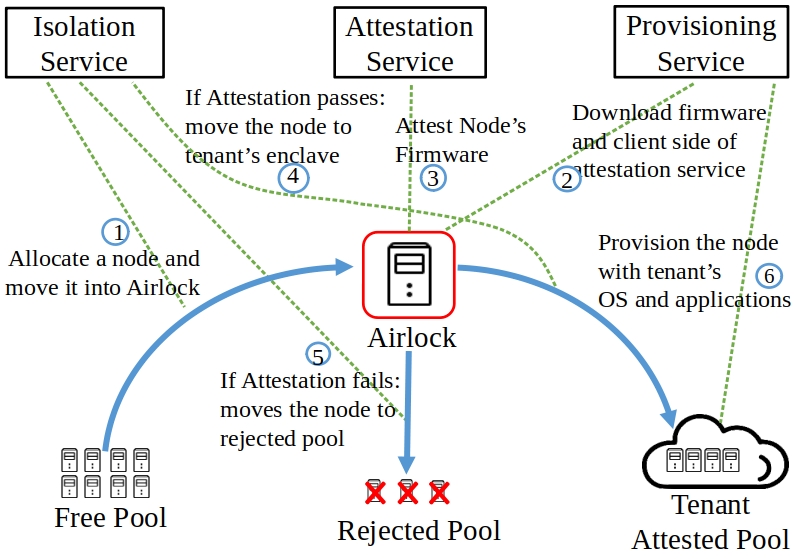
Current Research
Distributed Storage
The values offered by public cloud services are clear for analytic workloads. Specialized hardware such as GPUs for doing AI/ML may make more sense to effectively lease with Opex rather than invest Capex on infrastructure that is not continually utilized. However, it may not make sense to build large data sets inside public clouds due both to the cost multiple compared to building out and maintaining private infrastructure and the lock-in nature of using public cloud services. These drivers then lead toward a hybrid architecture where large data sets are built and maintained in private clouds, but compute/analytic clusters are spun up in public clouds to the actual analytics on these data sets.
Maintaining a hybrid architecture as described introduces challenges with latency and bandwidth to the public cloud compute cluster from the private data lake.
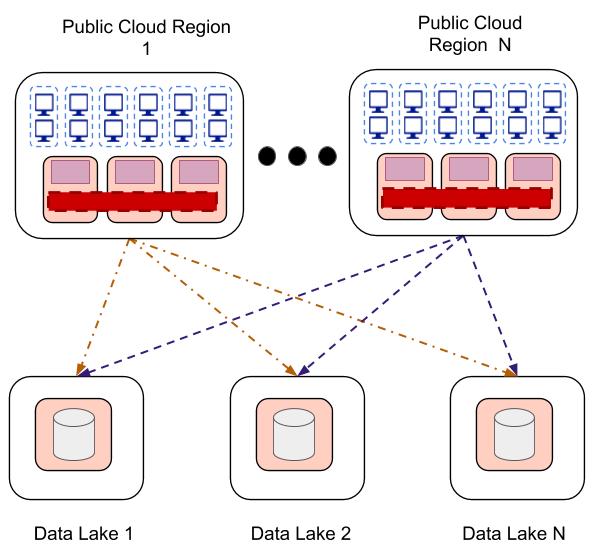
In this project, we design and implement a new hybrid cloud caching architecture to maximize throughput of these leased analytics clusters and avoid re-reading the same data from the external private data lake. In the first step, we explore caching policies, building on our original D3N work that integrated a read-only distributed cache into Ceph’s S3 implementation (i.e., the Rados Gateway (RGW)).
We have implemented a durable write back cache and built a distributed directory that is critical to implementing the different policies that we want to explore.
While the focus is on the research that we expect to explore with this platform, to support real workloads it is critical that the work is properly integrated into the complex Ceph code base. Therefore, all the changes are reviewed with the lead RGW developers, and a set of changes are already being integrated upstream. this work will be the first step in an aggressive research agenda on hybrid cloud. I am interested in exploring how caching of immutable object storage can be used to enable data to be efficiently accessed by multiple tenants from multiple datalakes in many cloud regions; essentially creating a global storage system.
Caching System
To get good performance for data stored in Object storage services like S3, data analysis clusters need to cache data locally. Recently these caches have started taking into account higher-level information from analysis framework, allowing prefetching based on predictions of future data accesses. There is, however, a broader opportunity; rather than using this information to predict one future, we can use it to select a future that is best for caching.
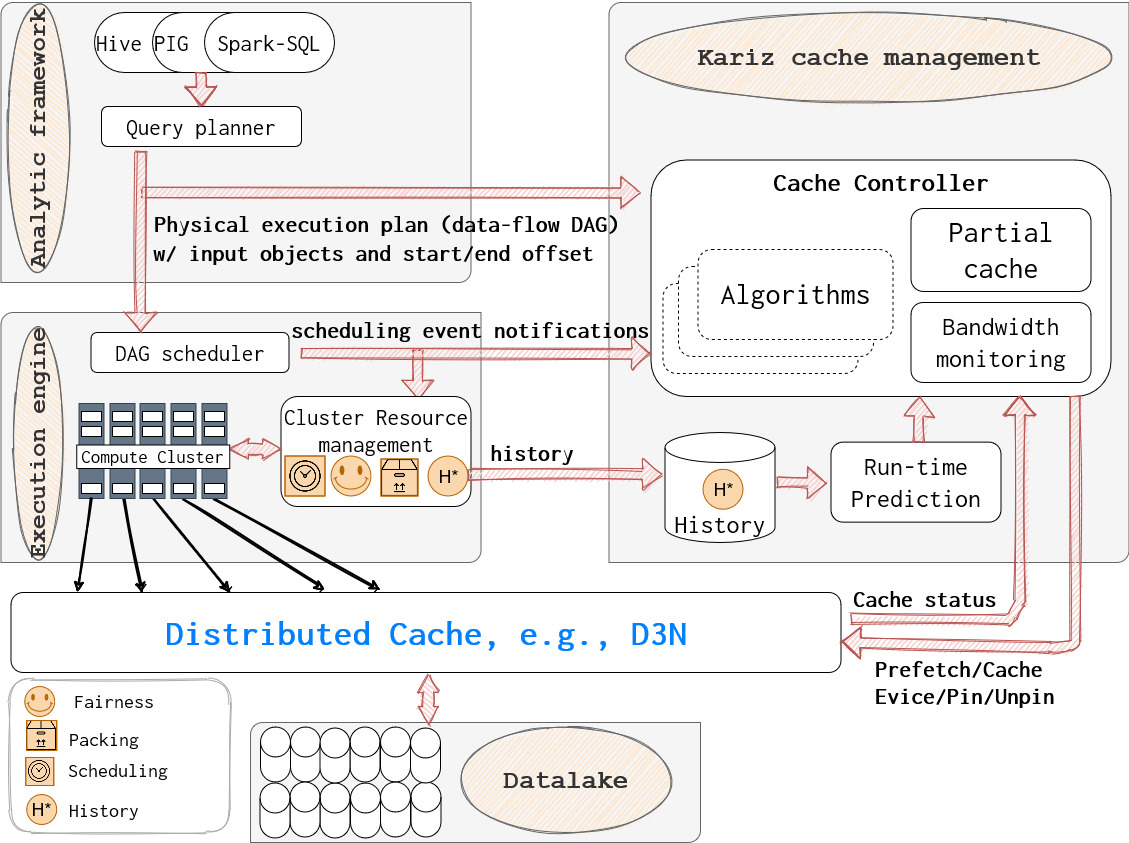
The goal of this project is to develop a system for caching and prefetching analytic framework input data accessed from remote storage. This project aims to exploit the directed acyclic graph (DAG) of inter-task dependencies used by data-parallel frameworks such as Spark, Pig, and Hive to improve application performance, by optimizing caching for the critical path through the DAG for the application. It integrates a cross-DAG scheduler, giving preference to prefetching input data shared by multiple DAGs, while bounding unfairness in service.
Workload Generator
One fundamental challenge for all of these storage research projects is the lack of publicly available workloads to exercise and validate the research.
Existing traces are either old, miss critical information (e.g., locality, user information and sometime even write operation) or both. In addition, existing benchmarks are not relevant. Fio, for example, is intended for stress testing not evaluating a whole system. Another problem is that the traces available from industry collaborators are usually restricted and therefore results of evaluation of the system are not publishable.
Our goal in this project is to develop a workload generator that can be used to evaluate storage systems which is: 1) consistent with real world workloads 2) validated with real traces 3) can scale up or down (e.g., to support larger cluster, or produce larger set of files) 4) enables sensitivity analysis of the system and 5) enables other researcher to create new models consistent with their traces
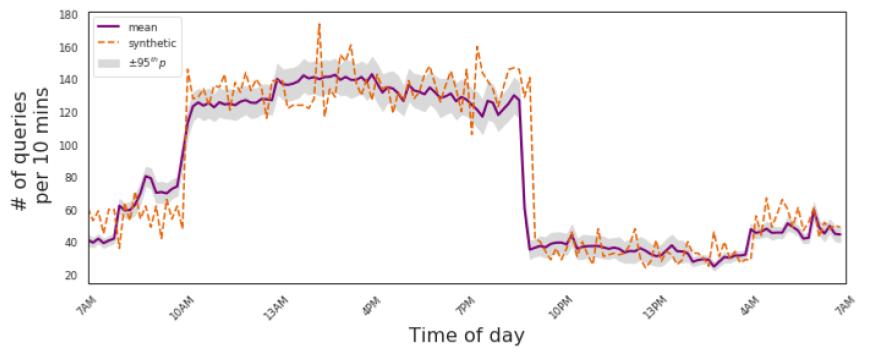
To do this, we first analyze the industry traces we have. In this way, we can understand and extract key characteristics of the traces (such as job inter-arrival time, size of files, characteristics of queries(DAGs), user behavior, …). In the next step, we model trace characteristics based on statistical distribution (e.g., model job submission inter-arrival time with poisson distribution, object size with heavy tail distributions). Another important step is to understand the correlation between different trace charactristics (e.g., DAG size - dataset size, reuse behavior, …). Based on the constructed models, we choose a set of queries from a pool of queries of representive benchmarks (e.g., TPC-H and TPC-DS). The generated synthetic trace tcan be used to exercise simulation or real storage systems.
Validation is the last important step. We need to compare simulated storage system’s behavior using the generated and original traces to be sure that the synthetic trace is accurate and useful.
Previous Research
Elastic Secure Infrastructure
Bolted is a bare metal cloud architecture to support security sensitive tenants. Security sensitive tenants are entities such as hospitals or financial institutes that have both the expertise and desire or requirement to trust their own security arrangements over those of a cloud provider. This work is a collaboration between the Mass Open Cloud and our industry partners.